HashMap是我们平台开发中最经常使用数据结构之一。很多人肯定是使用过很多次HashMap,但是至于HashMap的源码实现,可能很多人就没什么概念了。本文来介绍一下Java中HashMap的源码实现。
本文基于JDK1.8
常量定义
DEFAULT_INITIAL_CAPACITY
1 | /** |
- map的默认大小,默认是1 << 4=16,必须是2的幂
MAXIMUM_CAPACITY
1 | /** |
- map的最大容量,默认是1 << 30
DEFAULT_LOAD_FACTOR
1 | /** |
- 默认装载因子,默认是0.75f,超过这个值就需要进行扩容
TREEIFY_THRESHOLD
1 | /** |
- 由链表转换成树的阈值,一个桶中bin(箱子)的存储方式由链表转换成树的阈值
- 即当桶中bin的数量超过TREEIFY_THRESHOLD时使用树来代替链表。默认值是8
UNTREEIFY_THRESHOLD
1 | /** |
- 由树转换成链表的阈值
- 当执行resize操作时,当桶中bin的数量少于UNTREEIFY_THRESHOLD时使用链表来代替树。默认值是6
MIN_TREEIFY_CAPACITY
1 | /** |
- 当桶中的bin被树化时最小的hash表容量
- 如果没有达到这个阈值,即hash表容量小于
MIN_TREEIFY_CAPACITY,当桶中bin的数量太多时会执行resize扩容操作 - 这个
MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4倍
成员变量
table
1 | /** |
- 存放KV数据的数组
- 第一次使用的时候被初始化,根据需要可以重新resize
- 分配的长度总是2的幂
entrySet
1 | /** |
- 当被调用entrySet时被赋值
- 通过keySet()方法可以得到map key的集合
- 通过values方法可以得到map value的集合
size
1 | /** |
- 存放在map中的KV映射的总数
modCount
1 | /** |
- HashMap被结构性修改的次数
- 结构性修改是指改变了KV映射数量的操作或者修改了HashMap的内部结构(如 rehash)
- 这个用于fail-fast
threshold
1 | /** |
- 当需要resize时的阈值
- 即当HashMap中KV映射的数量(即size)超过了threshold就会resize
- threshold=capacity*loadFactor
loadFactor
1 | /** |
- 装载因子
capacity
- 成员变量中并没有capacity这个数据
- 当然capacity可以通过threshold和loadFactor计算得来
内部数据结构
node
1 | /** |
- hash指的是key对应的hash值
- 其成员方法hashCode为node对象的hash值
- 在成员变量table中引用的就是这个Node
transient Node<K,V>[] table;
- 其实在HashMap中大部分用到的是链表存储结构,很少用到树形存储结构
- 其实,理想情况下,hash函数设计的好,链表存储结构都用不到
静态工具方法
hash()
1 | /** |
为什么要有HashMap的hash()方法
- 难道不能直接使用KV中K原有的hash值吗?
- 在HashMap的put、get操作时为什么不能直接使用K中原有的hash值?
为什么要这么干呢?
这个与HashMap中table下标的计算有关
indexFor方法1
2n = table.length;
index = (n-1) & hash;因为table的长度都是2的幂,因此index仅与hash值的低n位有关,hash的高n位都被与操作置0了
假设table.length=2^4=16

- 由上图可以看到,只有hash值的低4位参与了运算
- 这样做很容易产生碰撞,这样就算散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,碰撞问题会更明显。
- 为了解决上述问题,设计者权衡了speed、utility, and quality,将高16位与低16位异或来减少这种影响
- 仅仅异或一下,既减少了系统的开销,也不会造成因为高位没有参与下标的计算(table的长度较小时),从而引起的碰撞
- 从上面的代码可以看出,key的hash值的计算方法
- key的hash值高16位不变,低16位与高16位异或作为key的最终hash值
- h >>> 16,表示无符号右移16位,高位补0,任何数跟0异或都是其本身,因此key的hash值高16位不变。
- 混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
为什么HashMap的容量要是2的幂
- 因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。
- 以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。
1
2
3
410100101 11000100 00100101
& 00000000 00000000 00001111
----------------------------------
00000000 00000000 00000101 //高位全部归零,只保留末四位
tableSizeFor()
1 | /** |
这个方法被调用的地方:
1
2
3
4
5public HashMap(int initialCapacity, float loadFactor) {
/**省略此处代码**/
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}由此可以看到,当在实例化HashMap时,如果给定了
initialCapacity,由于HashMap的capacity都是2的幂,因此这个方法用于找到大于等于initialCapacity的最小的2的次幂(initialCapacity如果就是2的幂,则返回的还是这个数)下面分析这个算法
- 首先为什么要对cap做减1操作
int n = cap - 1;- 这是为了防止cap已经是2的幂
- 如果cap已经是2的幂,又没有执行这个减1操作,则执行完后面的 几条无符号右移操作后,返回的capacity将是这个cap的2倍
- 下面看几个无符号的右移操作
- 如果n这时为0(经历了cap-1之后),则经过后面的几次无符号右移依然是0,最后返回的capacity是1,(最后有个n+1的操作)
- 这里只讨论n不等于0的情况
- 第一次右移
n |= n >>> 1;- 由于n不等于0,则n的二进制表示中总会有一个bit为1,这时考虑最高位的1
- 通过无符号右移1位,则将最高位的1右移了一位,在做或操作,便得n的二进制表示中与最高位的1紧邻的右边一位也为1,如000011xxxxxx
- 第二次右移
n |= n >>> 2;- 注意这个n已经做过
n |= n >>> 1;操作 - 假设此时n为000011xxxxxx
- 则n无符号右移两位,会讲最高位两个连续的1右移两位,然后再与原来的n做或操作,这样n的二进制表示的高位中会有4个连续的1,如00001111xxxxxx
- 第三次右移
n |= n >>> 4;- 这次把已经有的高位中的连续的4个1,右移4位
- 再做或操作
- 这样n的二进制表示的高位中会有8个连续的1。如00001111 1111xxxxxx
- 依次类推
- 注意,容量最大也就是32bit的正数
- 因此最后
n |= n >>> 16; - 最多也就32个1,但是这时已经大于了
MAXIMUM_CAPACITY - 所以取值到
MAXIMUM_CAPACITY
- 第一次右移
举个例子
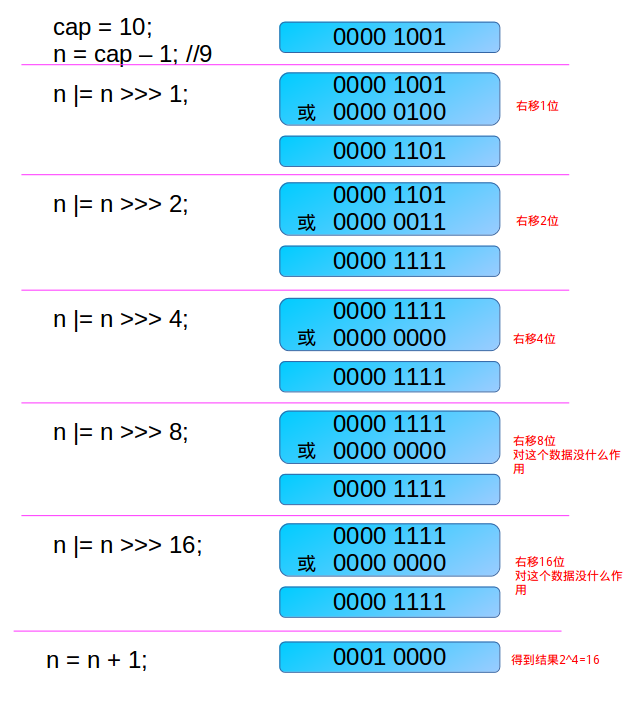
- 首先为什么要对cap做减1操作
- 注意,得到的这个
capacity却被赋值给了thresholdthis.threshold = tableSizeFor(initialCapacity);- 这不是一个bug,因为在构造方法中,并没有对table这个成员变量进行初始化
- table的初始化被推迟到了put方法中,在put方法中会对
threshold重新计算
get()
1 | /** |
- 上面的注释中说的比较重要的一点就是,如果返回值是null,并不是一定没有这种KV映射,也可能是该key映射的值value是null,即key-null映射
- 也就说,使用get方法并不能判断这个key是否存在,只能通过containsKey来实现
- 由此可见get方法调用的是getNode方法,返回一个Node
- getNode方法接受两个参数hash值和key值
- 首先判断first node,在判断的时候,先看hash值是否相等,再看地址是否相等,再看equals的返回值
- 然后再遍历,判断first是不是树节点,是的话,在树中查找,否则,遍历链表
containsKey()
1 | /** |
put()
1 | /** |
- put方法将KV放在map中
- 如果,该key已经存放在map中,则用新值直接替换旧值
- put的返回值:如果该key已经存放在map中,则返回其映射的旧值;如果不存在,则返回null,表示没有该key对应的映射值(也可能原来的映射是key-null)
- 当new HashMap实例时,并没有初始化其成员变量
transient Node<K,V>[] table;,也就是说并没有为table分配内存 - 只有当put元素时才通过resize方法对table进行初始化
- 因此,建议需要先了解一下
resize方法 - put方法分为两种情况
- bucket是以链表形式存储还是以树形结构存储
- 如果key已存在则修改旧值,并返回旧值
- 如果key不存在,则执行插入操作,返回null
- 如果是插入操作还要modCount++
- 但如果是链表存储时,如果插入元素之后超过了TREEIFY_THRESHOLD,还要进行树化操作
- 注意,put操作,当发生碰撞时,如果是使用链表处理冲突,执行尾插法。这个跟
ConcurrentHashMap不同,ConcurrentHashMap执行的是头插法。因为,其HashEntry的next是final的
put的基本操作流程
- 通过hash值得到所在bucket的下标,如果为null,表示没有发生碰撞,则直接put
- 如果发生了put,则解决发生碰撞的实现方式:链表还是树
- 如果能够找到该key的节点,则执行更新操作,无需对
modCount增1 - 如果没有找到该key的节点,则执行插入操作,需要对
modCount增1 - 在执行插入操作时,如果bucket中bin的数量超过
TREEIFY_THRESHOLD,则要树化 - 在执行插入操作之后,如果size超过了
threshold,则需要扩容
resize()
1 | /** |
注释翻译
- 初始化或者翻倍表大小。如果表为null,则根据存放在threshold变量中的初始化capacity的值来分配table内存(这个注释说的很清楚,在实例化HashMap时,capacity其实是存放在了成员变量threshold中,注意,HashMap中没有capacity这个成员变量)。如果表不为null,由于我们使用2的幂来扩容,则每个bin元素要么还在原来的bucket中,要么在2的幂中
代码解析
newCap与newThr
1 | Node<K,V>[] oldTab = table; |
- 如果
oldTab != null,则oldCap>0;- 如果此时
oldCap >= MAXIMUM_CAPACITY,则表示已经到了最大容量,这时还要往map中放数据,则阙值设置为整数的最大值Integer.MAX_VALUE,直接返回这个oldMap的内存地址 - 如果此时oldCap< MAXIMUM_CAPACITY,表示还没到达最大容量
- 如果进行扩容后
newCap < MAXIMUM_CAPACITY并且 oldCap的初始化值大于等于DEFAULT_INITIAL_CAPACITY(16),则将threshold扩大一倍。因为threshold=capacity*loadFactor,capacity变成原来的2倍,则threshold也要变成原来的2倍。
- 如果进行扩容后
- 如果此时
- 如果
oldTab==null,则oldCap=0:- 如果
oldThr>0,表示在实例化HashMap时,调用了HashMap的带参构造方法,初始化了threshold,这时将阈值赋值给newCap,因为在构造方法 中是将capacity赋值给了threshold。 - 如果
oldThr<=0,表示在实例化HashMap时,调用的是HashMap的默认构造方法,则newCap和newThr都使用默认值
- 如果
这时要判断newThr是否等于0
newThr等于0表示
1
2
3else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
>= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double thresholdoldCap>0,这一步判断失败,有可能是扩容后大于了
MAXIMUM_CAPACITY,也有可能是oldCap小于DEFAULT_INITIAL_CAPACITY导致的
和oldCap1
2else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;判断成功,oldThr大于0
- 然后根据newCap和loadFactor确定newThr。有可能这时newCap已经大
于MAXIMUM_CAPACITY了,则将thresHold设置为最大的整数,否则直接使用计算得来的新的newThr。
- 下面就是分配内存,如果oldTab == null,则 返回newTab。
- 如果
oldTab = null,则需要将原内存地址中的数据拷贝给newTab的地址
下标的变化
- 例如我们从16扩展为32时,具体的变化如下所示
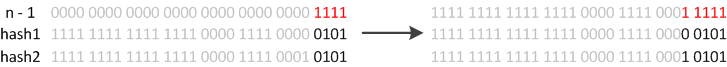
- 其中n即表示容量capacity。resize之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化
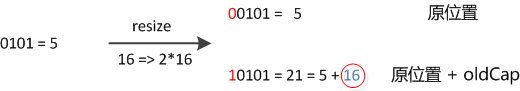
- 因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
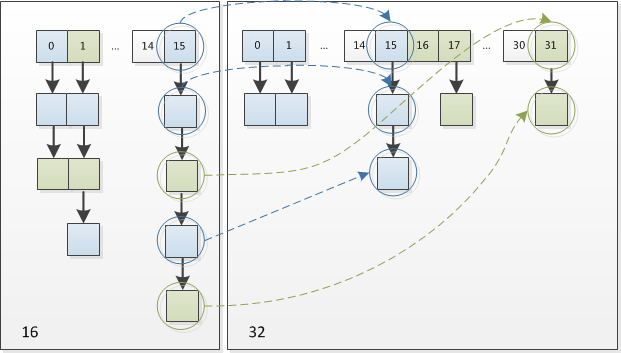
- 这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
- 在链表中进行操作时,使用的是尾插法