Tair是由淘宝网自主开发的Key/Value结构数据存储系统,在淘宝网有着大规模的应用。您在登录淘宝、查看商品详情页面或者在淘江湖和好友“捣浆糊”的时候,都在直接或间接地和Tair交互。
Tair于2010年6月30号在淘宝开源平台上正式对外开源,本文较详细地介绍了Tair提供的功能及其实现的细节,希望对大家进一步了解Tair有所帮助。
Tair是提供快速访问的内存(MDB引擎)/持久化(LDB引擎)存储服务,基于高性能、高可用的分布式集群架构,满足读写性能要求高及容量可弹性伸缩的业务需求。
功能
Tair是一个Key/Value结构数据的解决方案,它默认支持基于内存和文件的两种存储方式,分别和我们通常所说的缓存和持久化存储对应。
Tair除了普通Key/Value系统提供的功能,比如get、put、delete以及批量接口外,还有一些附加的实用功能,使得其有更广的适用场景,包括:
- Version支持
- 原子计数器
- Item支持
Version支持
Tair中的每个数据都包含版本号,版本号在每次更新后都会递增。这个特性有助于防止由于数据的并发更新导致的问题。
比如,系统有一个value为a,b,c,A和B同时get到这个value。A执行操作,在后面添加一个d,value为a,b,c,d。B执行操作添加一个e,value为a,b,c,e。如果不加控制,无论A和B谁先更新成功,它的更新都会被后到的更新覆盖。
Tair无法解决这个问题,但是引入了version机制避免这样的问题。还是拿刚才的例子,A和B取到数据,假设版本号为10,A先更新,更新成功后,value为a,b,c,d,与此同时,版本号会变为11。当B更新时,由于其基于的版本号是10,服务器会拒绝更新,从而避免A的更新被覆盖。B可以选择get新版本的value,然后在其基础上修改,也可以选择强行更新。
原子计数器
Tair从服务器端支持原子的计数器操作,这使得Tair成为一个简单易用的分布式计数器。
Item支持
Tair还支持将value视为一个item数组,对value中的部分item进行操作。比如有个key的value为[1,2,3,4,5],我们可以只获取前两个item,返回[1,2],也可以删除第一个item,还支持将数据删除,并返回被删除的数据,通过这个接口可以实现一个原子的分布式FIFO的队列。
架构
Tair整体架构图
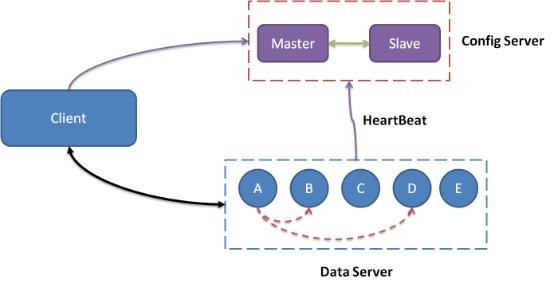
系统架构
一个Tair集群主要包括3个必选模块:ConfigServer、Dataserver和Client.
通常情况下,一个Tair集群中包含2台Configserver及多台DataServer。其中两台Configserver互为主备。通过和Dataserver之间的心跳检测获取集群中存活可用的Dataserver,构建数据在集群中的分布信息(对照表)。Dataserver负责数据的存储,并按照Configserver的指示完成数据的复制和迁移工作。Client在启动的时候,从Configserver获取数据分布信息,根据数据分布信息,和相应的Dataserver进行交互,完成用户的请求。
从架构上看,Configserver的角色类似于传统应用系统的中心节点,整个集群服务依赖于Configserver的正常工作。而实际上,Tair的Configserver是非常轻量级的,当正在工作的Configserver宕机的时候,另一台会在秒级别时间内自动接管。而且,即使出现两台ConfigServer同时宕机的恶劣情况,只要DataServer没有新的变化,Tair依然服务正常。应用在使用时只需要连接Configserver,而不需要知道内部节点的情况。
ConfigServer
两台Configserver互为主备
通过和Dataserver之间的心跳检测来获取集群中存活、可用的Dataserver节点信息
根据获取的Dataserver节点信息构建数据在集群中的分布表
提供数据分布表的查询服务
调度Dataserver之间的数据迁移、复制
DataServers
提供存储引擎
接受Client发起的put/get/remove等操作
执行数据迁移、复制
访问统计
client
提供访问Tair集群的API
更新并缓存数据分布表
LocalCache,避免过热的数据访问影响Tair集群服务。
流量控制
产品功能
分布式架构
采用分布式集群架构,具备自动容灾及故障迁移能力。
支持负载均衡,数据均匀分布。
支持弹性扩展系统的存储空间及吞吐性能,突破海量数据高 QPS 性能瓶颈。
丰富易用的接口
数据结构丰富,支持单级 key-value 结构,同时也支持二级索引结构。
可支持多种应用场景,支持计数器模式。
支持数据过期和版本控制。
应用场景
数据库缓存
随着业务量上升,数据库收到的并发请求数会不断增加,随之而来的问题就是数据库系统的负载升高,响应延迟下降,严重的时候,甚至有可能因此而导致服务中断。为了解决这类问题,可以将Tair MDB产品与数据库产品搭配使用,组成高吞吐、低延迟的存储解决方案。
MDB响应速度快,通常在几毫秒内即可完成请求。另一方面,MDB可支持更高的QPS,处理比数据库更多的并发请求。用户通过业务观察,将热点数据放置在MDB中,可以极大缓解数据库的负载,不仅可以节省数据库成本,而且提高了系统的可用性。
临时数据存储
应用程序需要维护大量临时数据,例如社交网络、电子商务、游戏、广告等,将临时数据存储在MDB中,可以降低内存管理的开销,改进应用程序工作负载。在分布式环境中,可以将MDB作为全局统一存储,避免单点故障造成的数据丢失,同时解决多个应用程序之间的同步问题。
常用的例子是将MDB作为session manager使用,如果网站采用分布式部署,且访问量很高,那么同一个用户的不同请求可能会发送到不同的web服务器上,这时可以用MDB作为全局存储,用于保存Session数据、用户的Token、权限信息等数据。
数据存储
推荐或广告类业务通常需要离线计算大量数据。LDB支持持久化存储,且性能优异,支持数据的在线化服务,因此,用户可将离线数据定期导入LDB提供在线服务。
榜单类业务也可通过计算后,将最终的榜单信息存储在LDB,并直接展示给前端应用。既可满足存储需求,也可以满足快速访问的需求。
黑白名单
安全类应用有较多黑白名单场景,该类黑白名单场景具有命中率低,访问量大,数据丢失业务有损等特性。LDB支持数据持久化功能,同时也支持高访问量,因此被广泛应用于此类场景。
分布式锁
为防止因多线程并发造成的数据不一致或逻辑混乱,分布式锁是比较常见的处理方式。利用Tair的version特性或者计数功能可以实现分布式锁。由于LDB具有持久化功能,当服务有出现宕机的情况,也不会因此出现锁丢失或者锁不可释放的情况。